Usually, when I get really invested in some piece of open-source software, I like to discover how other people in the world are using it — mainly for personal curiosity, but also to learn what the true potential of that technology can be in the field. This is especially true with all that kind of software used for making websites, including CMSes… which, for these last few days, has been meaning HTMLy for me.
Unfortunately, regarding this matter, HTMLy is in kind of a tough spot. It’s not at all widely known, so it’s absolutely unlikely to stumble on someone using it or even just recommending it, and it doesn’t even have its own gallery of sites (like instead some static site generators do, eg. Docusaurus). But, at the same time, it has existed for enough time, and has enough eyes on it, that one can be statistically sure that at least a handful of sites on the web must be powered by it; so, it logically would be a shame to give up on such a time sink without at least trying.
Given that I have a lot of time to waste, it’s only natural that I was going to come up with my own ways to tackle this problem (one that for normal people wouldn’t even exist in the first place). So, from the obvious to the complex, let’s see all of them here, before either I forget them forever, or someone else steals my latest opportunity to make yet another post about HTMLy. Oh and, just to show off what can be achieved with these simple ways, in my notes I actually hold a list of random HTMLy websites, that I update whenever I feel like it; check it out: https://memos.octt.eu.org/m/DaaRwUFpfPPjrcTJen7ynN!
Using Standard Search Engines
As happens with virtually all content management systems, all HTMLy websites that haven’t been heavily modified from the default templates will have some kind of reference to the software, in their pages; a pretty unambiguous line crediting the engine, which can be searched literally on search engines to quickly filter to interesting results. Now, often those can come in any variety, but for HTMLy (and limiting my search to English) I’ve only found a few iterations around, which I’m writing below. (Quotes, which indicate to search engines to do an exact lookup, are added by me, to make copypasting easier.)
- “
Powered by HTMLy“ - “
Proudly powered by HTMLy“
Additionally, there are quite a few default strings in the program that end up being visible in public pages, if the user doesn’t change them. I’m obviously referring to things like the site’s tagline and users’ biography, which everyone knows about at least indirectly. Just like many WhatsApp users still have the default status of “Hey there! I am using WhatsApp” after more than a decade, and a lot of clueless WordPress admins in the past never changed that dreaded “Just another WordPress site.“, HTMLy offers these:
- Site tagline: “
Just another HTMLy blog“ - User description: “
Just another HTMLy user” (I’m personally guilty of this, as of editing this article…) - Site description: “
Proudly powered by HTMLy, a databaseless blogging platform.“
Advanced Search Techniques and Services
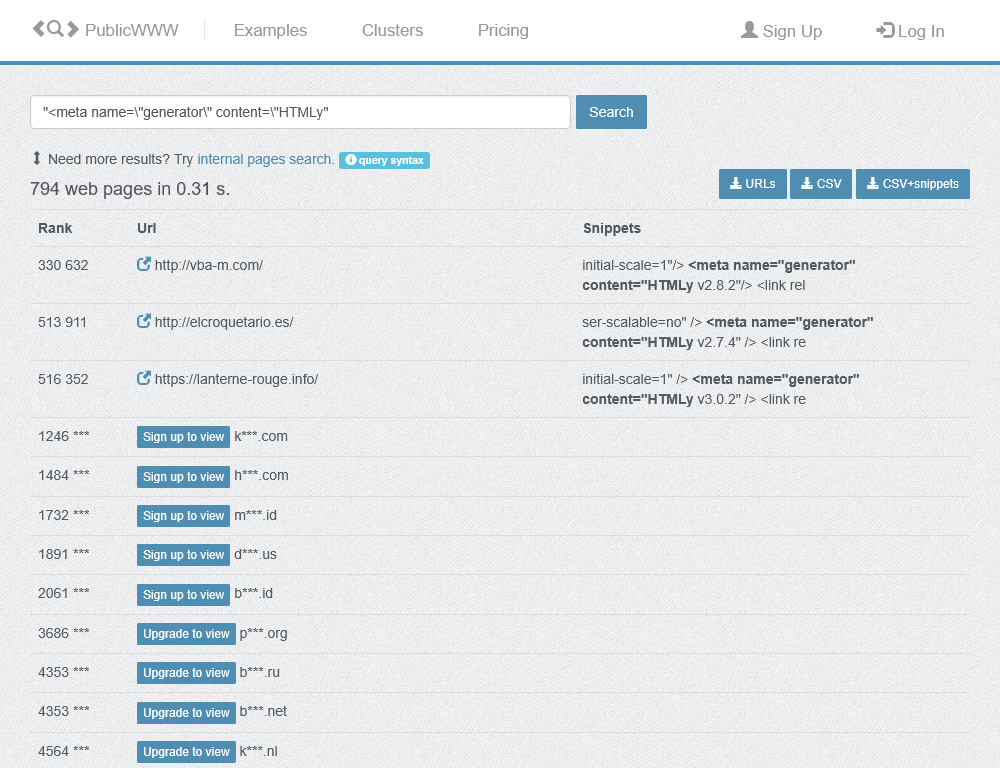
HTMLy, just like much other software of its kind, includes specific hidden metadata in the pages it generates, which can be used to identify a webpage — more or less, beyond any reasonable doubt — as being created by that given software and not any other one. Unfortunately, mainly for performance reasons, garden-variety search engines like Google or Bing don’t allow searching for raw HTML content, which is basically what is needed in this circumstance. Luckily, though, a few niche services exist to allow exactly this… they’re so niche, in fact, that even I don’t really know them, so for now I can only suggest a single one: PublicWWW, which unfortunately requires a hefty payment to view more than a few results.
You could try complex options and combination, searching for specific URL paths and file that happen to be used only really by HTMLy in the wild, but the most reliable approach is to leverage the standard HTML5 generator metadata, which is always present (unless site admins go out of their way to hide it by modifying the engine source code): just look for “<meta name="generator" content="HTMLy“ and you’ll find almost a thousand pages, actually.
Hanging Around the Community
The last method I can really suggest is this: just check out the HTMLy community, and the people in it. This is frankly the oldest trick in the book, and honestly not the most efficient, but it’s always a good one and, in some twisted ways, superior. In this case, it amounts to form a habit of checking out the project’s official GitHub page. This way, not only you can often gather many insights of how other people are using the software, but sometimes someone could drop a link to their website in an issue or discussion, or a contributor to the code could have their HTMLy blog listed on their profile, and you can just follow along to discover.
At this point, there’s nothing more of value left to say, I think. So, instead of wondering why I couldn’t in any way come up with some clever paragraph to close this article… why don’t you leave your own HTMLy website (or even just link any interesting ones that you know of) in the comments here? My magic methods listed here are still not bulletproof, and could have missed your specific site, so don’t be afraid to spam and just share!